


Section: New Results
Geometric and Visual Features Fusion for Action Recognition
Participants : Adlen Kerboua, Farhood Negin, François Brémond.
keywords: skeleton, geometric features, visual features, CNN.
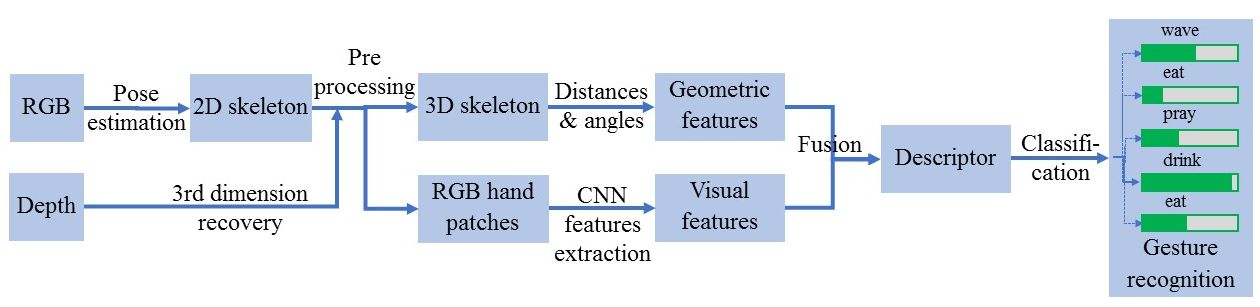
The proposed activity recognition system consists in the fusion of two types of features: geometric features and visual features. The geometric features are computed from the 2D/3D skeleton joints that represent the articulations of the human body, which can be extracted by modern methods of pose estimation from RGB/RGB-D images, such as DeepCut pose estimation [107] or OpenPose [51]. The visual features are extracted by a convolutional neural network CNN from RGB patches representing both hands, the main steps of this method are illustrated in Figure 28.
Geometric features
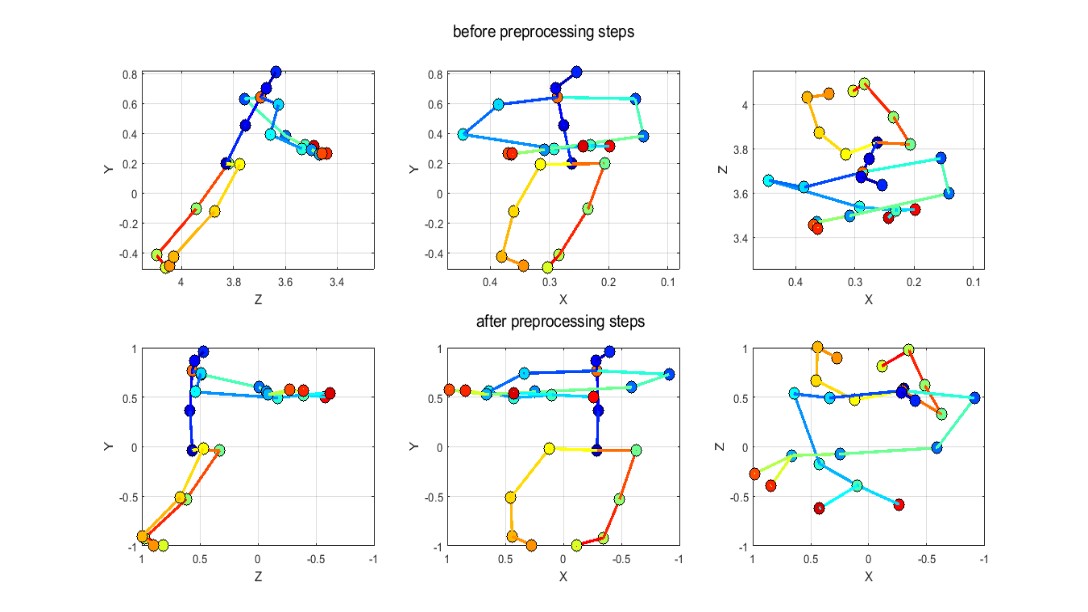
Before computing the geometrical features, we apply several preprocessing steps on the skeleton joints:
-
First, we reduce noise in joints estimation by smoothing joints position over frames by applying local regression using weighted linear least squares and a 2nd degree polynomial model.
-
Second, according to individual speed, similar action can be performed in different time duration by each subject resulting different number of frames, to uniform the skeleton information over frames we use cubic interpolation of the values at neighboring grid points in each respective dimension this method also permits to remove outliers joints wrongly estimated.
-
Then, in order to compensate variations in body sizes which can causes intra-classes variations and confuse the classifier, we follow the method presented in [135] by imposing the same limbs (skeleton segments) lengths for skeletons of all individuals in the dataset.
-
Finally, we compute rotations matrix for the first frame, then we apply same rotations for all frames in the video to remove the camera variations while keeping the over action dynamic, we also translate the skeleton to make the hip center of the first frame like the origin (figure 29).
To get the geometric features, we compute Euclidean distances and spherical coordinates (angles) between every skeleton joints pair-wise belonging to the same frame and adjacent frames.
Visual features
After the extraction of the skeletal joints during the precedent phase we can also extract the RGB patches representing the parts of the body most used to perform actions, which are in most cases the two hands, then we use several types of CNN (VGG16, VGG19, Resnet, ...) to extract the visual features. Different from our preliminary work of gesture recognition in the PRAXIS project, we merge those features with the geometrical one by concatenation to get the final descriptor used for classification of activities. During the test phase, a cross-subject test protocol is used to reduce the overfitting phenomenon and to obtain solutions that can be generalized.
Experiments
In the experimentation phase, we choose several datasets, including some properties of the STARS team, such as the PRAXIS dataset, this innovative test battery conducted on people with Alzheimer's disease is very useful to evaluate the evolution of this disease. This dataset contains more than 29 gestures divided between static and dynamic gestures, repeated several times by 58 patients, and contained a total of 3227 gestures performed in a correct manner and others in an inconsistent way. STARS also uses the most popular public datasets in the scientific community in order to evaluate the proposed methods compared to the current state of the art, such as NTU RGB+D [114] and ChaLearn [124].